Table of contents
Open Table of contents
Replication in kafka
Data replication is how kafka ensures fault tolerance. Topics are cut into non-overlapping partitions and each partitions can have multiple replicas. These replicas can be on different brokers, ideally one or less on each broker. So if one broker crashes, data is not lost and can still be served from other working brokers. While the redundancy ensures strong consistency, it has a trade-off of increased latency. However, the level of redundancy can be controlled from several features kafka provides like producer acks, replication factor and minimum in-sync replicas.
Minimum in-sync replicas
Before that here is something to remember:
replicationFactor > partitions (fine)
replicationFactor <= number of brokers (fine)
replicationFactor > number of brokers (NOPE, not possible!) Two replicas of same partition of same topic cannot exist on same broker
partitions > number of broker (fine) Number of partition is mostly consumer parallelism focusedReplication factor is defined for each topic at the time of topic creation with
--replication-factor option.
Similarly number of partitions is defined for each topic at time of creation with --partitions
option.
If not provided the default value of both is 1.
A replication factor of 3 means data will be stored on leader and 2 follower replicas.
While this replication happens a property min.insync.replicas ensures that this many replicas (
including the leader)
must write the data to its log file if the property on producer is acks=all. Default value of
min.insync.replicas is 1.
A message is not visible to consumers until message is replicated to the number of replicas
specified in min.insync.replicas.
With min.insync.replicas and acks=all, there is a high guarantee of durability of data.
min.insync.replicas ≤ replication.factormin.insync.replicas can be configure at both broker level as well as when we create topics.
Each partition replica leader tracks the lag of follower replica. The followers send fetech requests
to
leader to get latest logs. If the leader does not receive fetch request within
replica.lag.time.max.ms then
follower is considers out of sync and removed from ISR.
If the leader crashed then the new leader is elected from one of ISR if
unclean.leader.election.enable
is disabled. This can again be set on broker or topic creation time.
A very nice sequence diagram of kafka replication I found
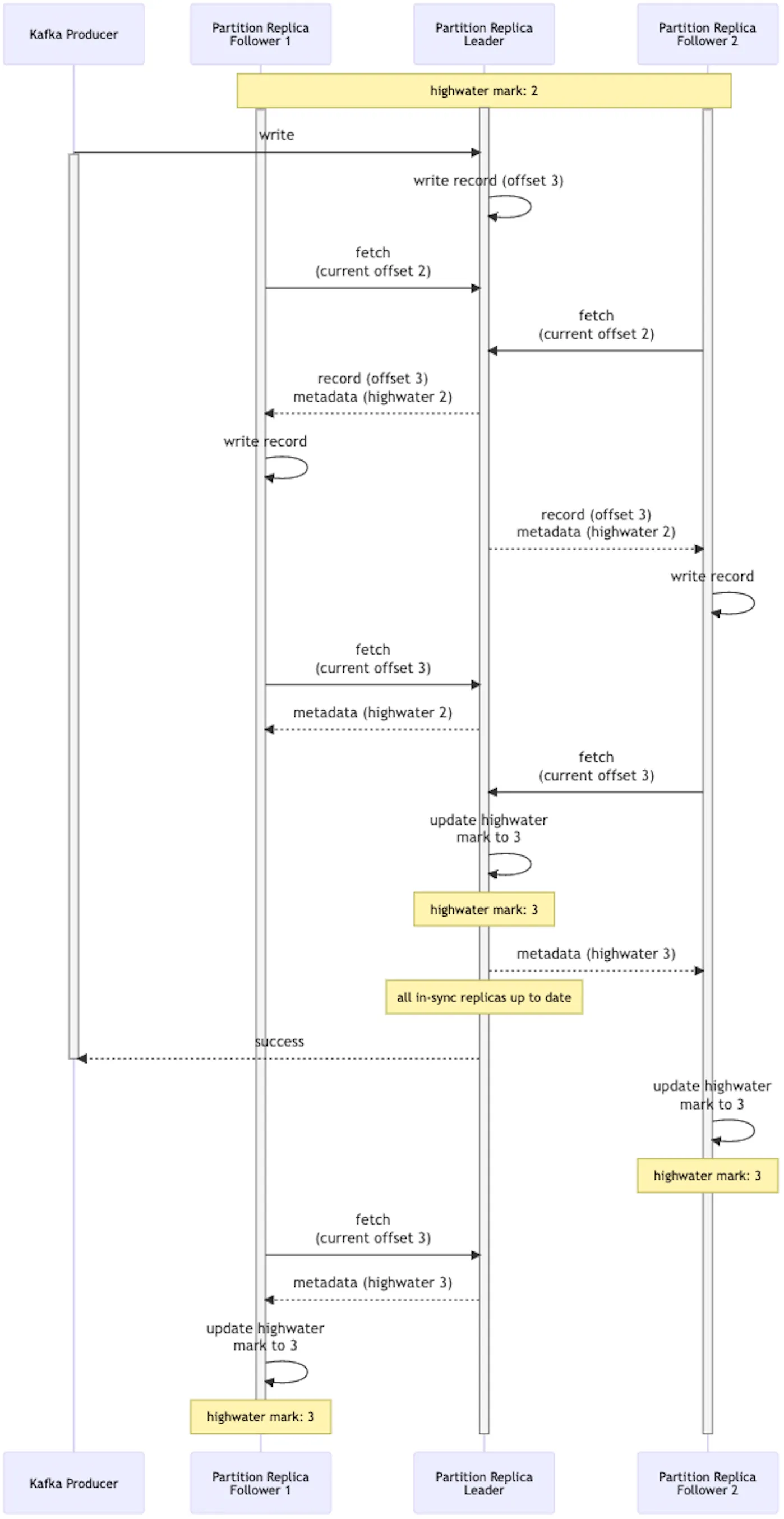 I dont know what highwater is yet though!
I dont know what highwater is yet though!
What are the benefits?
- High availability: Multiple up to date replicas through which consumers can get latest data
- High durability: It has “in-sync” in it
Tradeoffs
- Latency: Log is not visible to consumer until it is replicated to all ISR, same on producer side, producer client see some lag in successful produce. Latency is much higher when brokers are in different AZs.